Google selecting the wrong canonical URLs? Here’s how to fix “Duplicate without user-selected canonical” errors.
The first time I saw the dreaded “Duplicate without user-selected canonical” warning in Google Search Console, my heart sank. Not this. Please, not this.
But then it happened again… and again. And soon, I realized I wasn’t alone—other SEOs and digital marketers were reporting the same issue.
At first, I hoped it was just a glitch in Search Console, maybe another one of those temporary bugs we could ignore. But as the errors kept piling up, it became clear: this was real, and it had the potential to mess with indexing and visibility in a big way.
It’s one of the most frustrating Google Search Console errors out there—almost as questionable as the chunky sneaker trend (and that’s saying something).
The truth is, this issue isn’t going away on its own. As SEOs, it’s time we band together, share what we’ve learned, and figure out how to fix these “Duplicate without user-selected canonical” errors before they cause bigger indexing headaches.
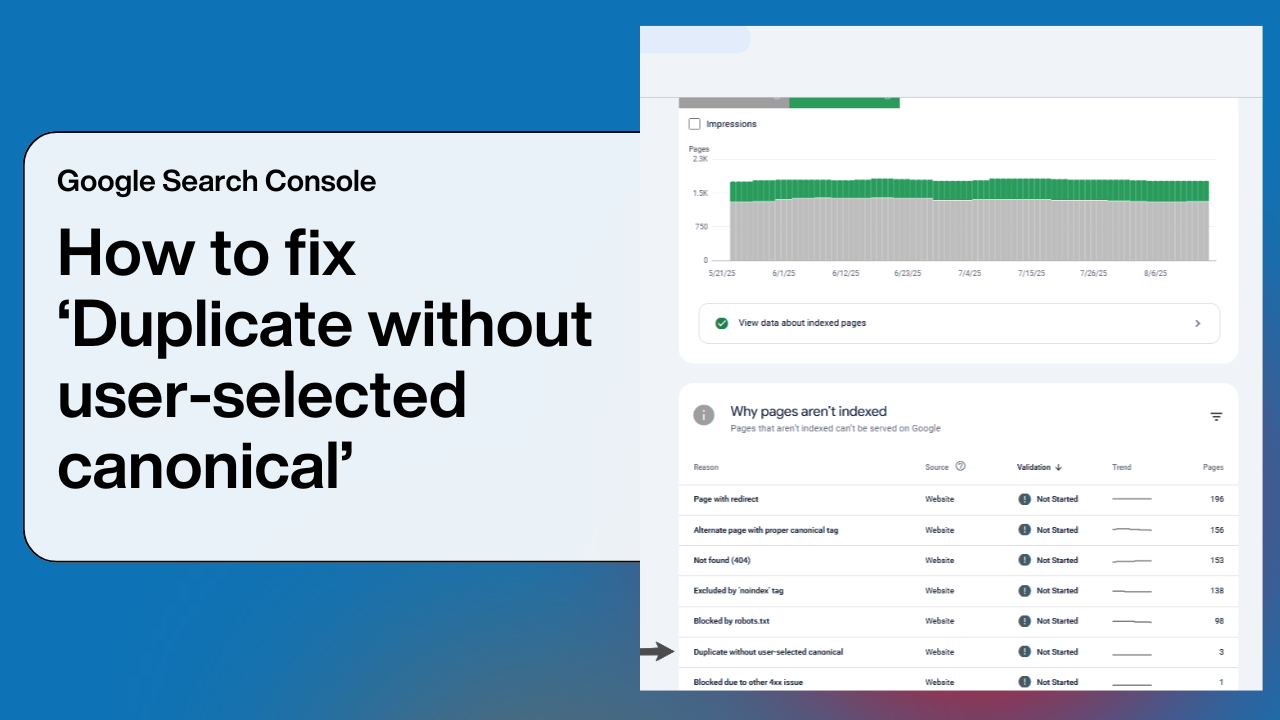
How do I fix a ‘Duplicate without user-selected canonical’ error in Google Search Console?
- Go to Google Search Console
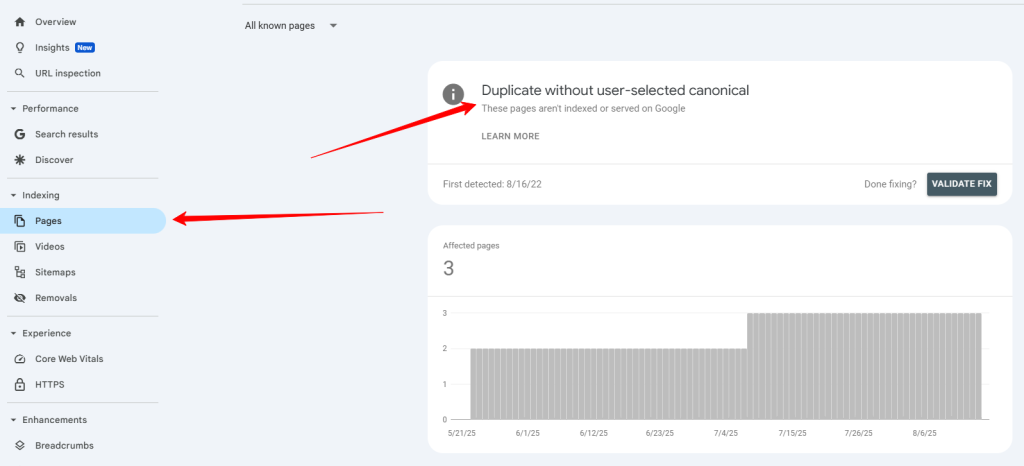
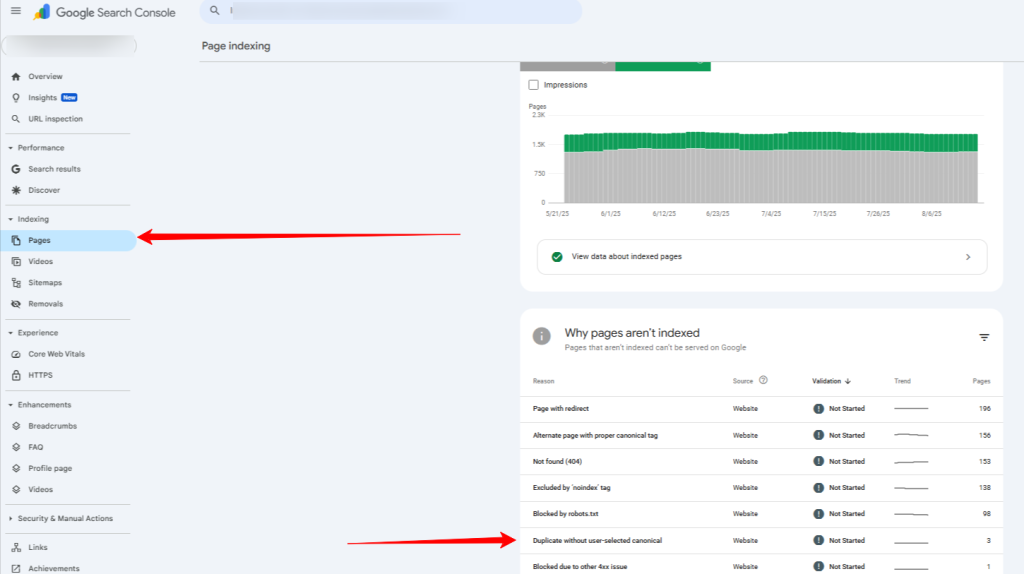
- Go to Pages
- Duplicate without user-selected canonical
Head over to Google Search Console’s Pages report and select the “Duplicate without user-selected canonical” error under the Why pages aren’t indexed section.
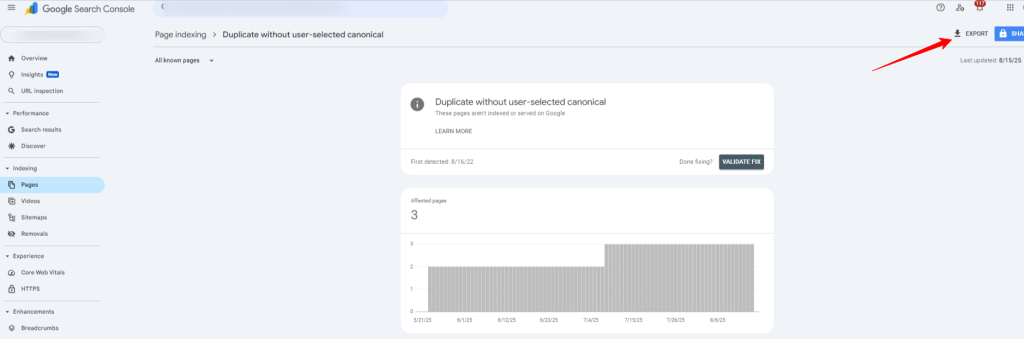
Once you’re in there, export the report into a spreadsheet.
2. Double-check your canonical tags
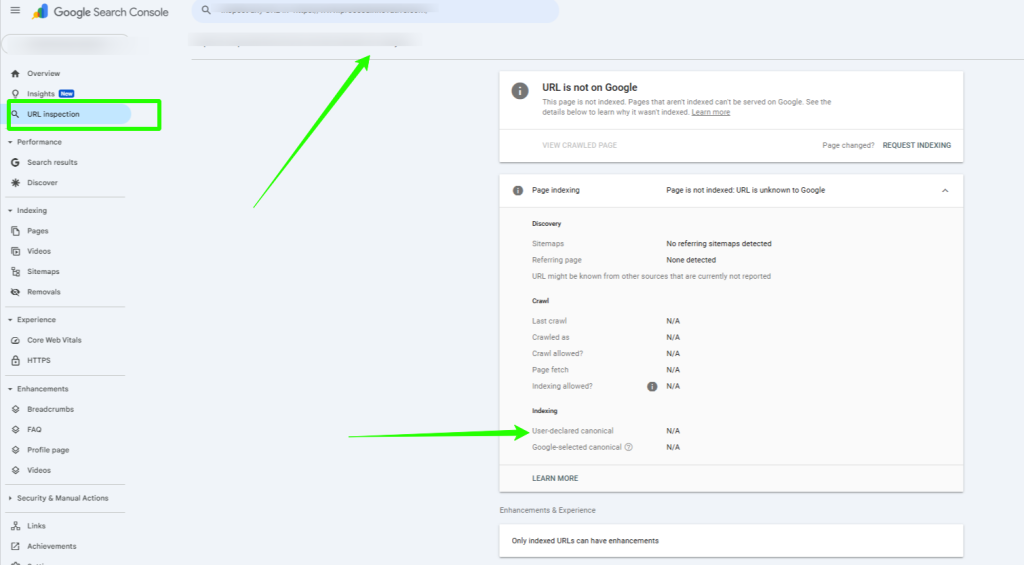
The next step is to manually review your canonical tags on a handful of URLs from the report. I usually check at least 10 using the Inspect URL tool in Google Search Console to get a good sample.
If you notice that Google keeps overriding your choice, it’s a strong signal that you should implement self-referencing canonical tags across your site.
Take the example below: this URL doesn’t have a declared canonical tag, so Google decides to pick one for you. And trust me—Google’s “best guess” isn’t always what you’d want.
Once you’ve got your spreadsheet of affected URLs, start filtering for the most common duplicate content issues. Many of these can be fixed with proper canonical tags:
- Parameter URLs – Anything after a ? (like tracking parameters) should point back to itself with a self-referencing canonical tag.
- Language subfolders – Double-check URLs with language subfolders (e.g., /en/, /fr/) to make sure they’re canonicals of themselves and not competing with the main version.
By spotting these patterns early, you’ll be able to clean up a big chunk of duplicate issues quickly—and save yourself from Google deciding which version it wants to rank.
3. HTTP vs. HTTPS
Another common reason this error pops up in Google Search Console is when the HTTP and HTTPS versions of your site aren’t properly consolidated.
Think of it this way: HTTP is like watching your favorite movie on an old VHS tape, while HTTPS is the same film in crystal-clear 4K streaming. Naturally, Google prefers the 4K experience—HTTPS.
For example:
- http://website.com/
- https://website.com/
Both versions might exist, but only one should be indexed. And as Google’s Gary Illyes put it:
“DYK that HTTPS URLs in a dup cluster have a higher chance of becoming canonical?”
If you still see HTTP versions showing up in your Search Console export, you’re essentially competing against yourself and diluting your rankings.
Fix:
- The best solution is to set up 301 redirects from HTTP to HTTPS.
- If that’s not possible, at minimum, add a self-referencing canonical tag to every HTTP variant to point to the HTTPS version.
4. Always include a trailing slash in URLs
If you want to avoid duplicate content headaches, make sure your URLs are consistent—and that means always using a trailing slash.
Consistency is the real key here.
As John Mueller from Google explained:
“The slash after a hostname or domain name is irrelevant… but a slash anywhere else is a significant part of the URL and will change the URL if it’s there or not.”
Translation: Don’t ignore the slash. Adding or dropping it actually creates two separate URLs in Google’s eyes.
For example:
- https://website.com/double-decker-taco
- https://website.com/double-decker-taco/
Google sees these as two different pages—even though they look the same to you.
Fix:
- Pick one version (with the trailing slash).
- Set up a 301 redirect from the non-slash version to the slash version.
That way, you keep things consistent and prevent Google from splitting authority between duplicate pages.
5. www vs. non-www
Picture this: you serve up the same dish twice—once on fine china, and once in a cardboard takeout box. Same ingredients, same flavor, but they look completely different.
That’s exactly how search engines view your www and non-www versions of a URL:
- https://www.tacosareawesome.com/
- https://tacosareawesome.com/
To Google, those are two entirely separate websites.
So which version should you use? Honestly, it doesn’t matter. There’s no SEO advantage to “www” over “non-www.” The key is consistency.
Fix:
- Pick one version (www or non-www).
- Set up a 301 redirect from the non-preferred version to the one you’ve chosen.
This way, you’ll consolidate authority, avoid duplicates, and make sure Google knows exactly which version to index.
6. Session IDs or Tracking Parameters
Session IDs and tracking parameters are like nachos—you’ve got the same base dish, but each plate comes topped with something a little different. One with cilantro. One with hot sauce. Another with a squeeze of lime.
To us, it’s still nachos. But to search engines? Each topping variation looks like a completely separate dish—and that means duplicate URLs.
For example:
- https://www.tacosareawesome.com/
- https://www.tacosareawesome.com/?utm=medium=referral/
Same page. Different URLs. Duplicate headaches.
Fix:
- Don’t use parameter-based URLs in your internal links.
- Always add a self-referencing canonical tag that points to the clean URL (without the tracking parameters).
- Use your robots.txt file to block common parameters like session IDs and UTMs.
Example:
User-agent: *
Disallow: /*?sessionid=
Disallow: /*?utm_source=
This way, you can keep serving nachos with all the toppings you want—without confusing Google’s palate.
7. Write Original Content
Google doesn’t technically penalize duplicate content, but it will filter out weaker or repetitive pages. Translation: your shiny new page might never even make it to the search results.
Here’s the problem: are you reusing the same intro, service description, or FAQ across multiple product or location pages? That’s like showing up to every party in the same exact outfit. You blend in, and nobody remembers you.
Instead, aim for at least 50% unique content on each page. Put the spotlight on what makes that page different—whether it’s the specific product details, regional information, or customer stories.
If your content feels templated, search engines are basically yawning their way through your site. To keep their attention (and your rankings), mix it up: add new angles, fresh insights, and relevant local or product-specific details.
Removing Duplicate Content: The Only Way Forward
Fixing duplicate content isn’t exactly new in the SEO world—it’s practically an ancient art form. Every SEO Specialist has wrestled with it at some point.
But if you’re staring at the dreaded “Duplicate without user-selected canonical” error in Google Search Console, here’s the tough love: it’s time to audit your content.
Because let’s be real—duplicate content has never been cool. Sure, maybe back in the early 2000s when people were gaming rankings with copy-paste tactics. That was the same era when Who Let the Dogs Out was on every radio station and FUBU was still in style.
Today? Duplicate content is a stain on SEO history. And it won’t just disappear on its own. The only way forward is to roll up your sleeves, remove or consolidate duplicates, and give Google (and your users) content that’s actually worth indexing.




